



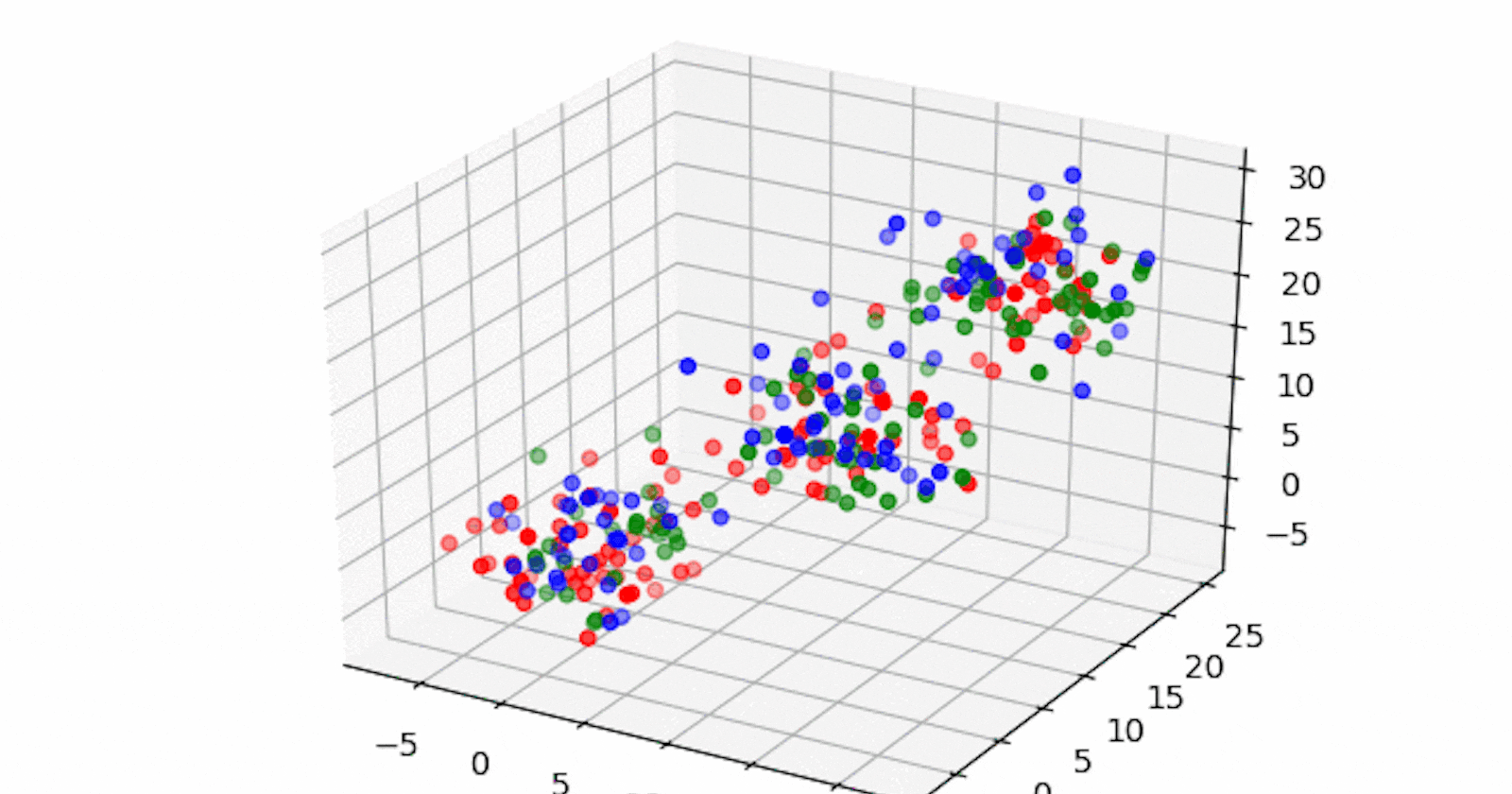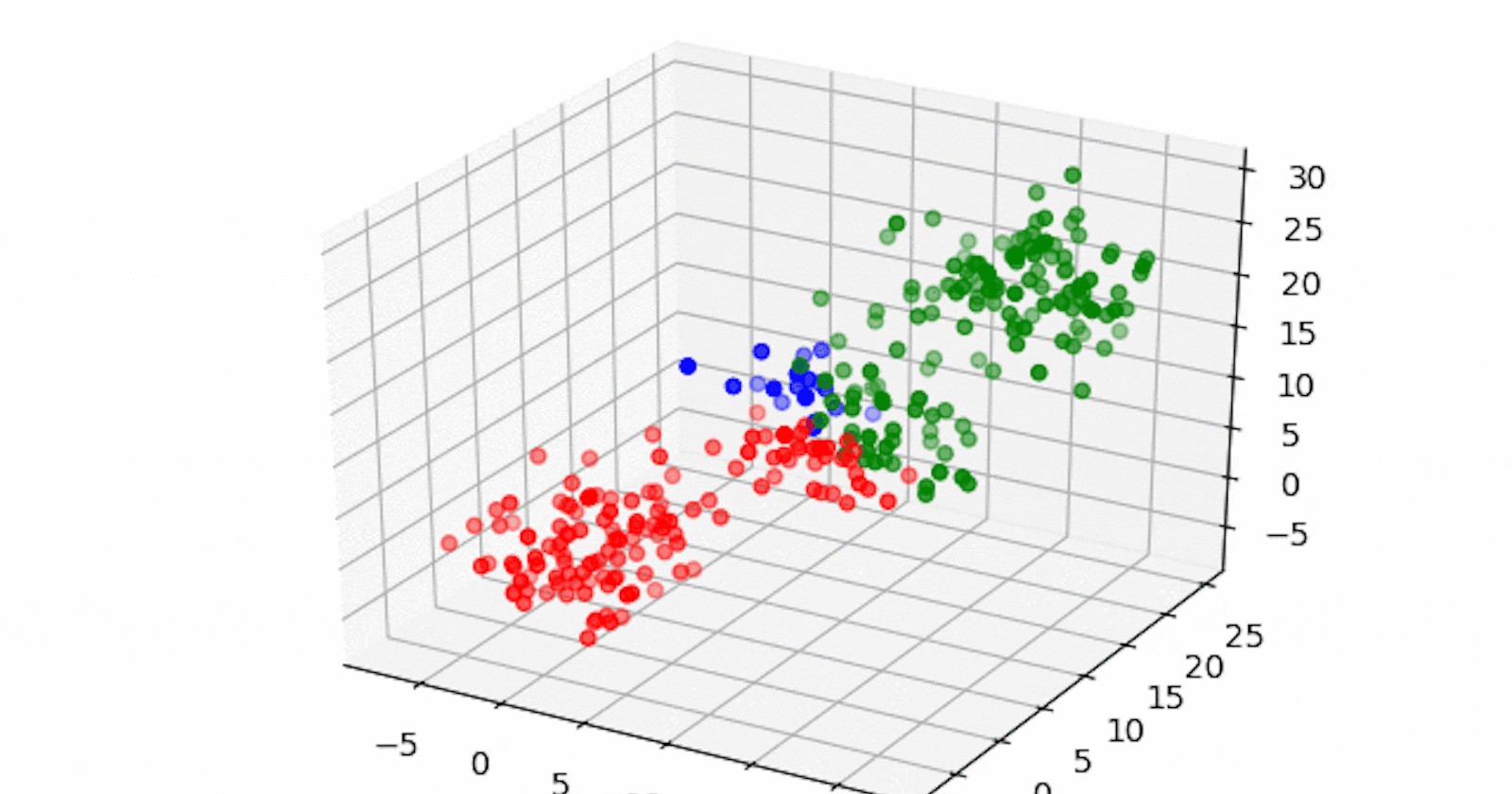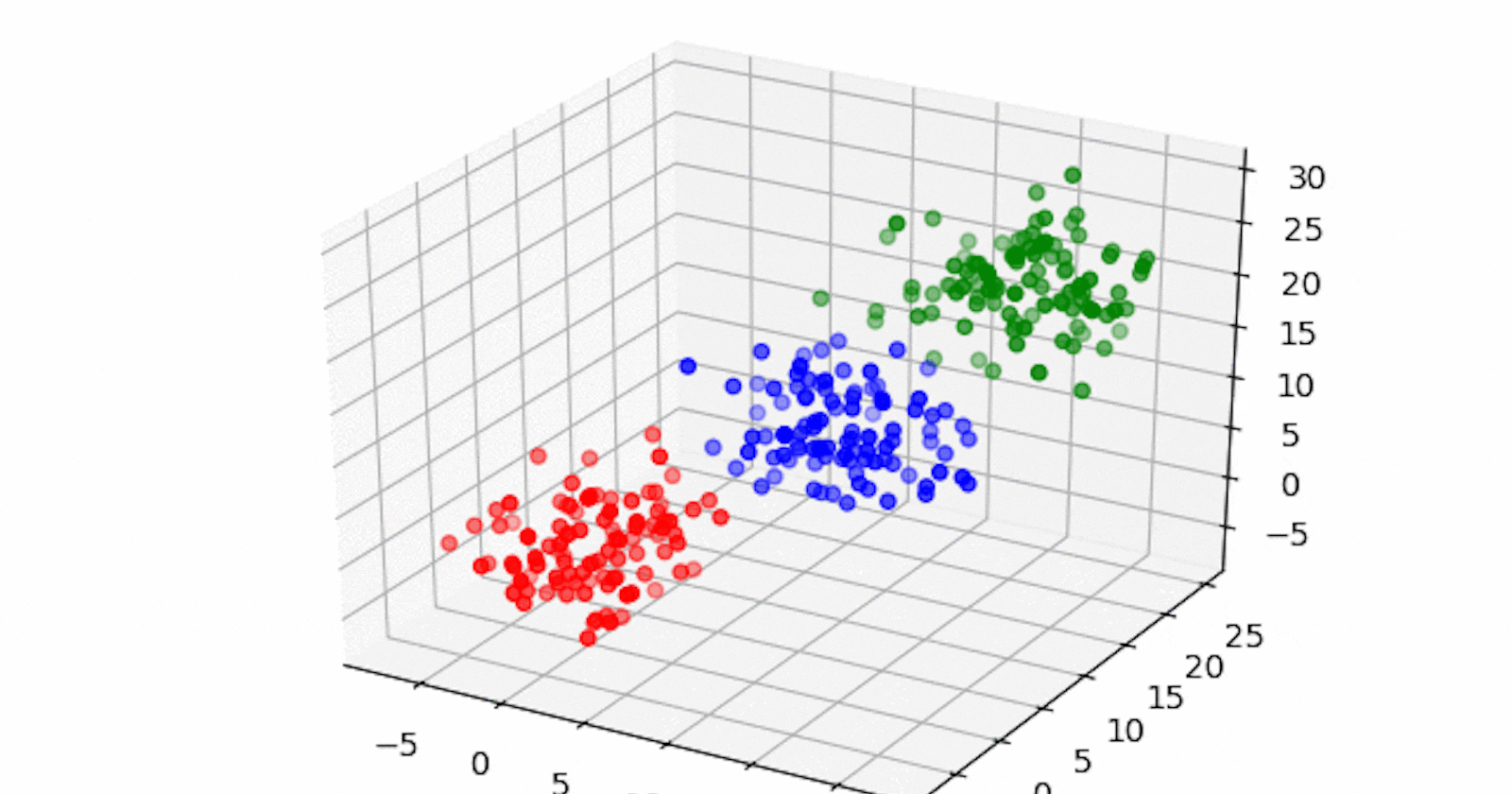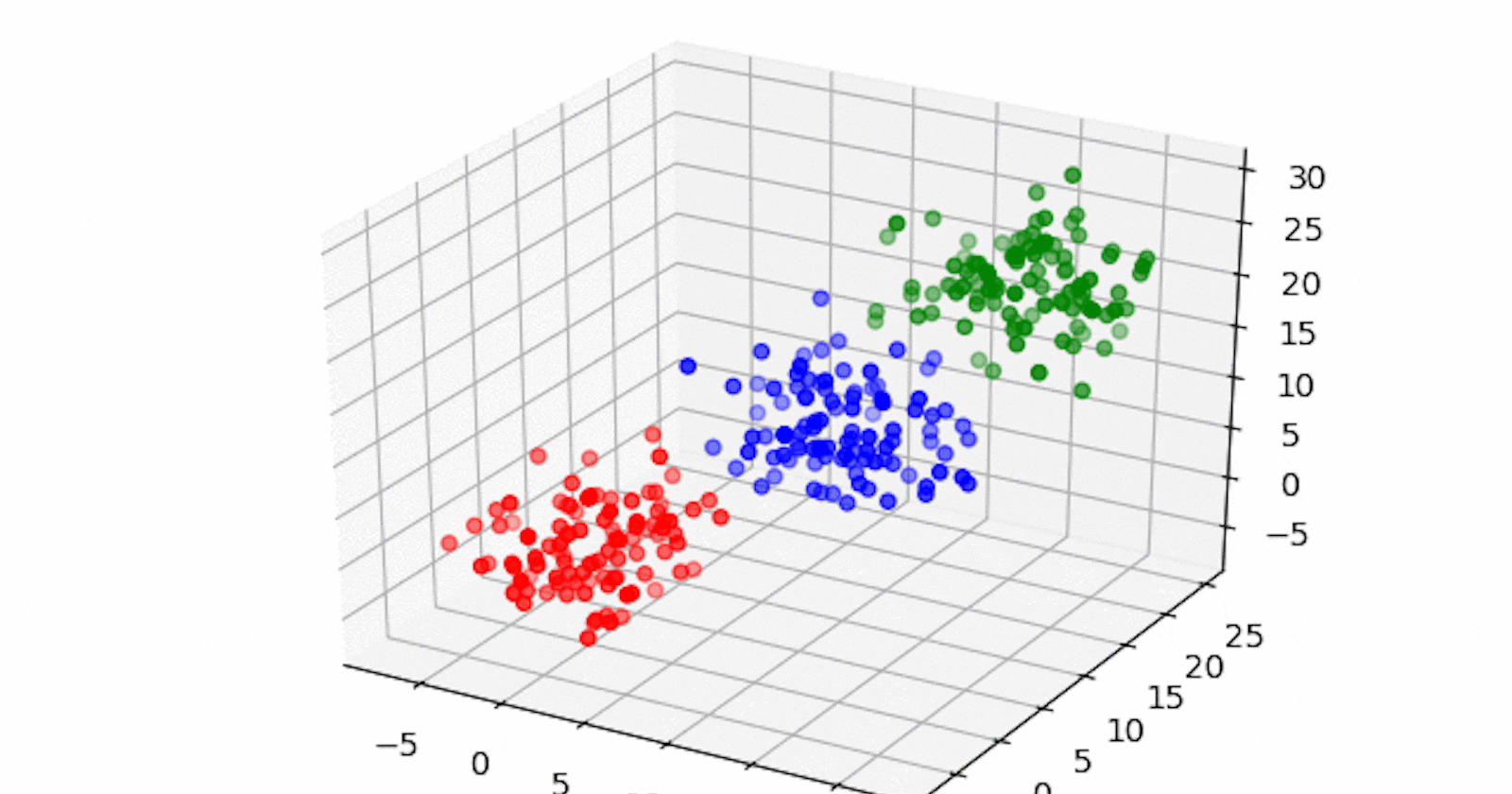
⚡IT infrastructure technology components such as network, storage, or database generate large volumes of alert messages. Because alert messages potentially point to operational issues, they must be manually screened for prioritization for downstream processes. Clustering of data can provide insight into categories of alerts and mean time to repair, and help in failure predictions.
🤔So what is meant by clustering ?
Consider there is a IT company with huge staff . HR department wants to give incentive to highly skilled and dedicated employees of each department on the basis and level of work he served for particular tenure.
A company has ample of departments and keeping manual track of each's work in the department with huge workforce would not be a cup of tea,also will take huge amount of one's time to do so.Thus company can split up the projects according to revenue generated from it as well as the client's feedback.Thus company now had certain number of employees in the group .lets say High ,Moderate and Low and likewise further cluster the things to achieve their goals.The process of grouping things is known as Clustering
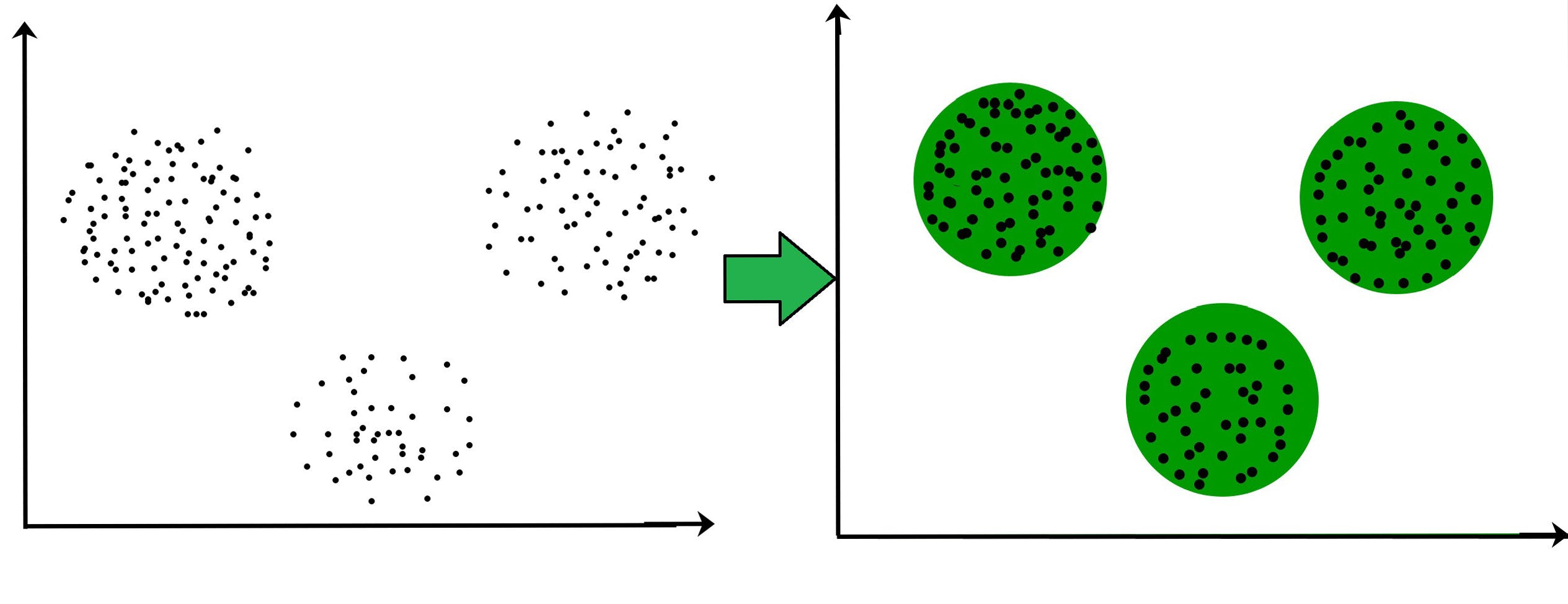
Clustering is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group than those in other groups. In simple words, the aim is to segregate groups with similar traits and assign them into clusters.
K-means Clustering algorithm is one of the most used for the above scenario, Thus lets peek in it.
k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean (cluster centers or cluster centroid), serving as a prototype of the cluster. This results in a partitioning of the data space into Voronoi cells. K-means clustering minimizes within-cluster variances (squared Euclidean distances), but not regular Euclidean distances, which would be the more difficult Weber problem: the mean optimizes squared errors, whereas only the geometric median minimizes Euclidean distances. For instance, better Euclidean solutions can be found using k-medians and k-medoids.
Mathematics behind K-Mean Clustering algorithm :
Assuming we have input data points x1,x2,x3,…,xn and value of K (the number of clusters needed). We follow the below procedure:
- Pick K points as the initial centroids from the dataset, either randomly or the first K.
- Find the Euclidean distance of each point in the dataset with the identified K points (cluster centroids).
- Assign each data point to the closest centroid using the distance found in the previous step.
- Find the new centroid by taking the average of the points in each cluster group.
- Repeat 2 to 4 for a fixed number of iteration or till the centroids don’t change.
Euclidean Distance between two points in space:
If p = (p1, p2) and q = (q1, q2) then the distance is given by
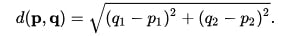
Applications of Clustering in Real-World Scenarios
Clustering is a widely used technique in the industry. It is actually being used in almost every domain, ranging from banking to recommendation engines, document clustering to image segmentation.

Nowadays, the network has become the basis of everything. Meanwhile, network security has become one of today's most urgent social problem. Intrusion detection systems are sold through real-time monitoring of network traffic, and take corresponding measures when the suspicious transfer of suspicious problems of a new network security device. Intrusion detection system compared to traditional network security measures, have great advantages.
Cluster analysis is a common method in data mining analysis, which can be used to show unsupervised anomaly detection, and can solve problems existing in traditional data mining methods. This method can be used in a new database without having to rely on pre-determined data categories and data category samples in intrusion detection system. Cluster analysis creates a good environment for the establishment of intrusion detection system.
Intrusion detection system is mainly to distinguish normal behavior and abnormal behavior and then make corresponding measures. In the midst of a data set, can through the simple data pre-processing and system audit, to use these data sets in our system, but this method is only used in simple normal behavior and behavior analysis, premise is to know the difference between the abnormal data and normal data.
By clustering algorithm, one group can not distinguish between normal and abnormal data processing, can summarize and find common ground, and then make a distinction. Clustering algorithm. Therefore, the application of unsupervised clustering algorithm in the field of abnormal detection can improve the detection efficiency of intrusion detection system and the practical application value is higher.
Conclusion The vast amount of data generated in the Internet era undoubtedly challenges the technology of large-scale data processing and data mining. Analysing the network security problems and performance better intrusion detection system in network security analysis simulation, let more people know the network intrusion behavior produces a variety of ways and means. In this way, we can ensure the security of the network information in the network information leak serious today.
Reference: Network Security Based on K-Means Clustering Algorithm in Data Mining Research Chunfen Bu1,a Department of physical science and technology, Kunming University 18459423@qq.com